Opossum vs Openfuse
Opossum
Alternative
Beyond the single-server breaker.
Opossum is a great circuit breaker for a single process. Openfuse takes it further: see every breaker across your fleet from one dashboard, change thresholds without deploying, and act on failures the moment they happen. Cloud or self-hosted.
No credit card required
Breakers
5 breakers across 5 services
stripe
payment-svc
sendgrid
notification-svc
postgres-replica
api-gateway
redis-cache
session-svc
inventory-api
order-svc
What you actually need at 2 AM
When a dependency goes down, you can open the dashboard, see every affected breaker across every service, and take control in seconds.
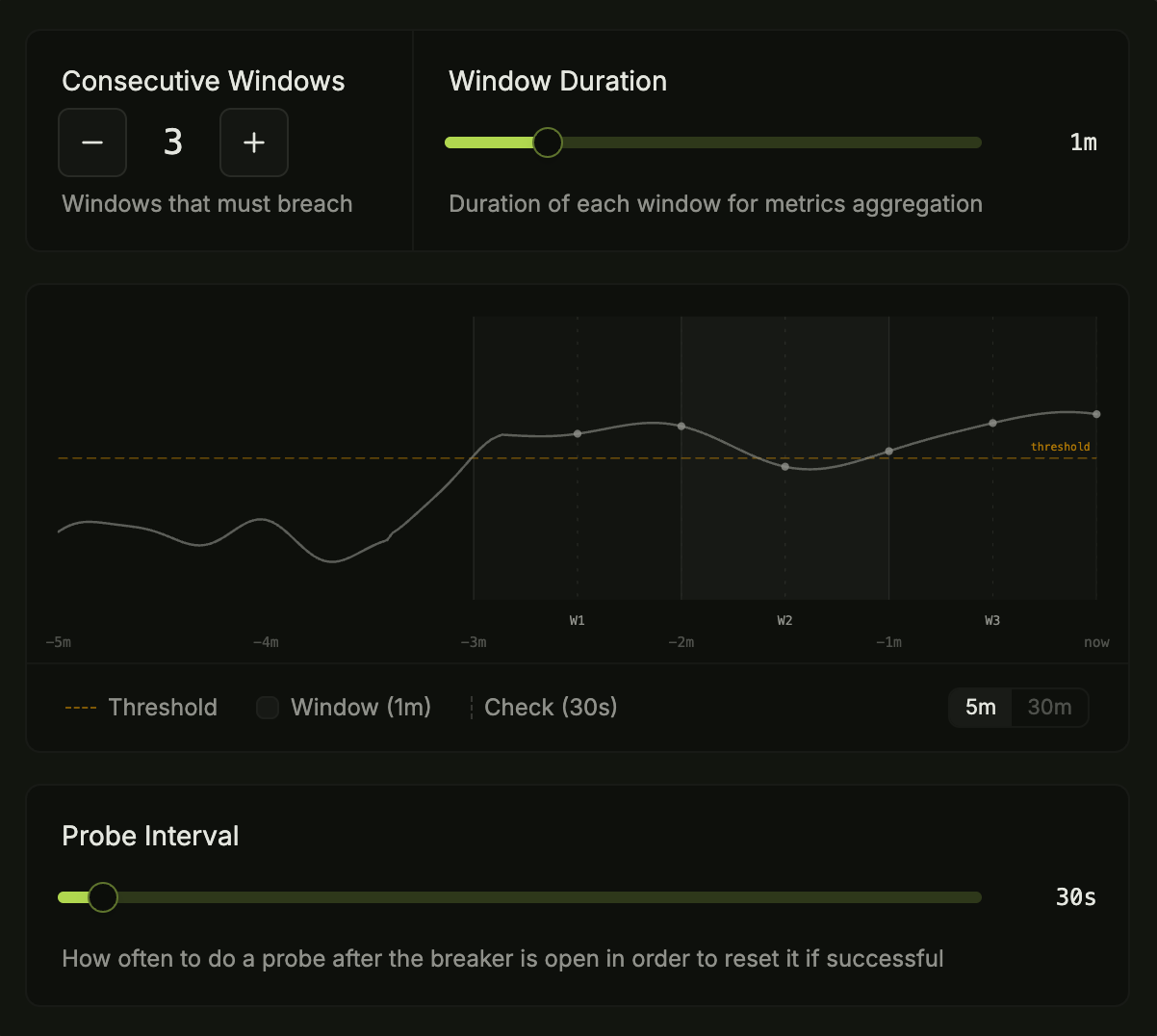
Trip policies from a dashboard
Configure error thresholds, evaluation windows, and recovery rules. Update them mid-incident without redeploying.
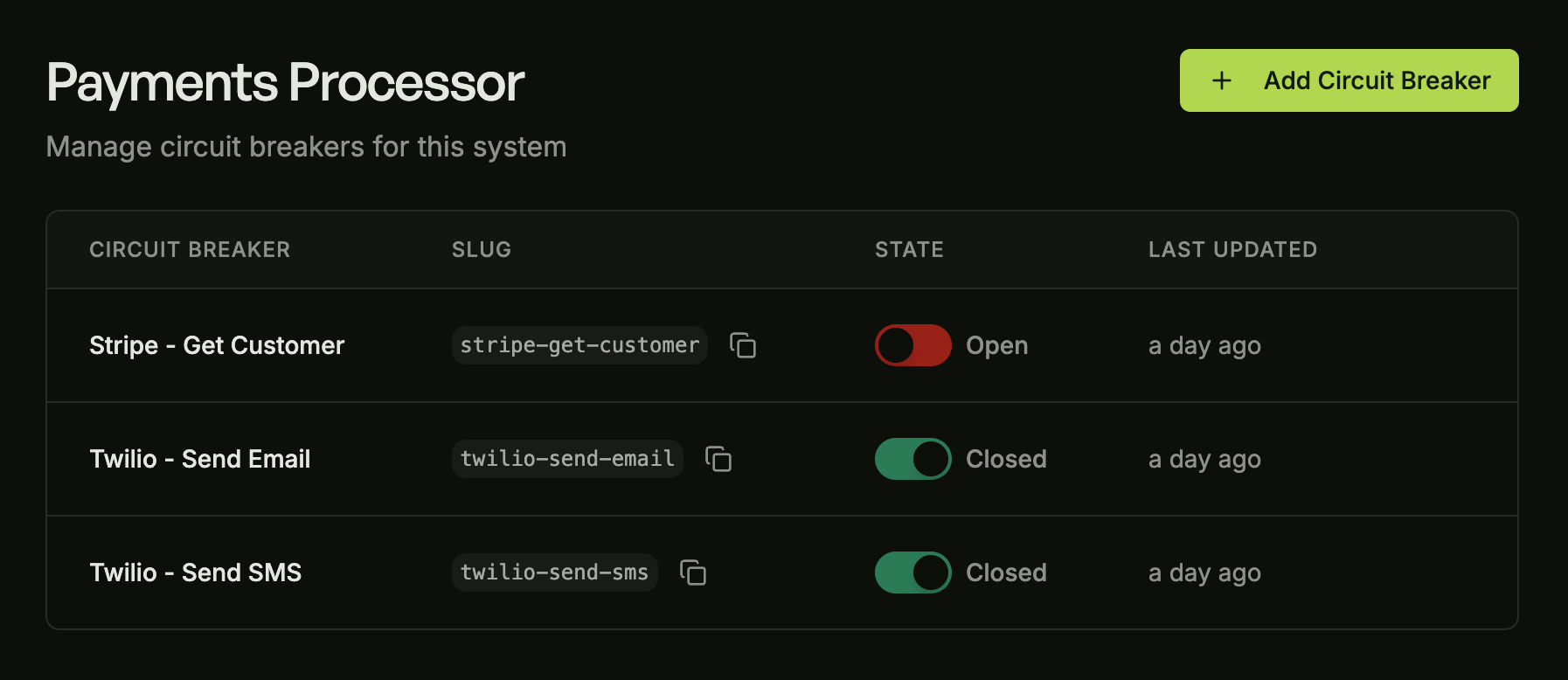
Manual overrides in one click
Open a breaker before a migration. Close it after a fix. No SSH, no deploy, no code changes needed.
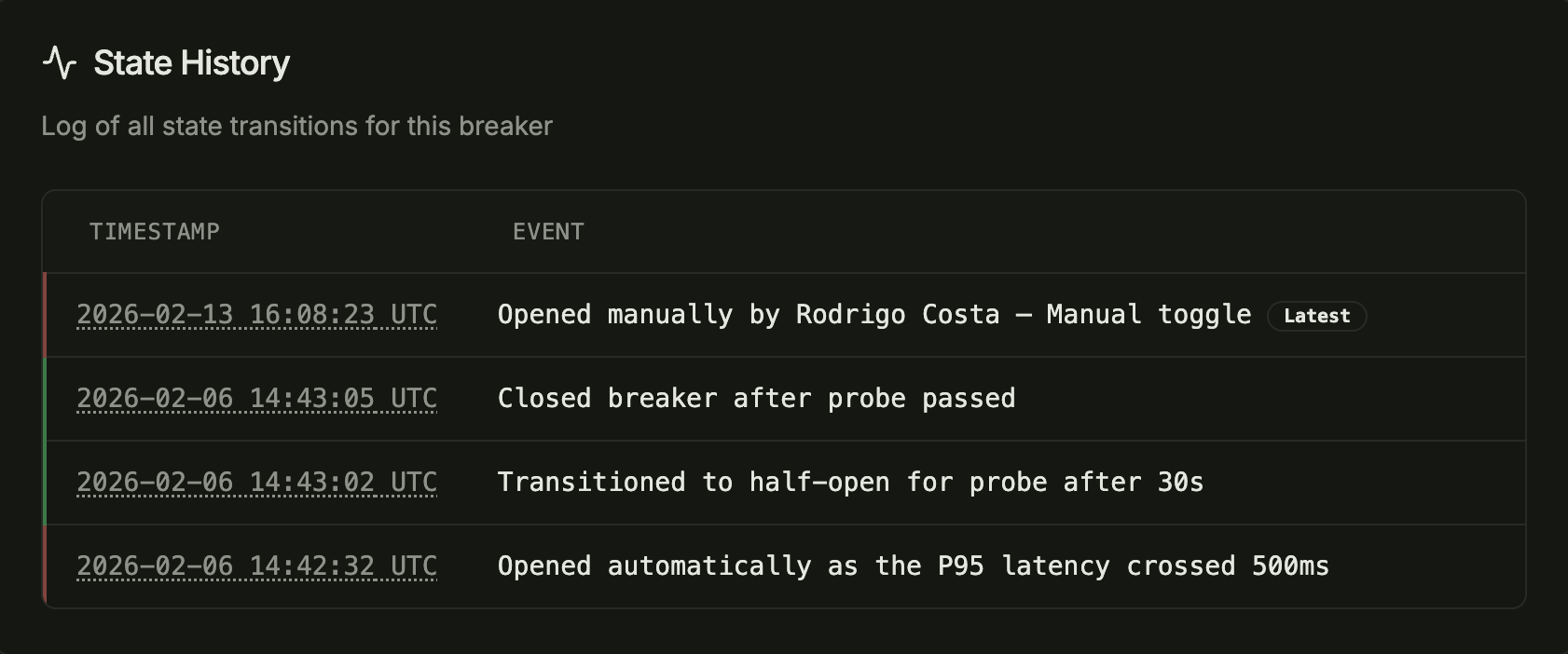
Full state history & audit trail
See every state transition with who triggered it, when, and why. Trace incidents to the exact moment.
No SSH, no redeploys, no guessing.
See the failure once. Act across your entire fleet.
With an in-process circuit breaker, when one instance of your services detects a failing dependency, it opens its local breaker. The other gateway instances keep calling. Your Payment Service keeps calling. Your Order Service keeps calling. Each one has to discover the failure independently.
With Openfuse, the moment a failure is detected, you see it in the dashboard and every instance across every service stops calling within seconds. No redundant failures, no cascading load, no waiting for each server to figure it out on its own.
Tuning thresholds mid-incident shouldn't require a deploy.
When thresholds live in code, changing a timeout means a code change, a PR, CI, and a deploy to every service. During an incident, that's exactly when you don't have time for a deployment pipeline.
With Openfuse, you change thresholds from the dashboard and they take effect across every instance in seconds. Open a breaker before a migration. Adjust a probe interval mid-incident. No code, no deploy.
12 services, 47 breakers. Which ones are open right now?
When breaker state is local, there's no single place to answer “what's the blast radius right now?” You'd need to check each service's logs or health endpoints individually, assuming you built that instrumentation yourself.
Openfuse gives you one dashboard showing every breaker across every service. Current state, recent trips, and a full audit trail. During an incident, your on-call can manually open or close any breaker with a single click. No SSH, no code.
Free for up to 10 breakers on our cloud, or self-host from day one.
No credit card, no sales call. Install the SDK, create a breaker, see it in the dashboard.
Side-by-side comparison
A quick reference for the differences that matter.
Minimal code changes
Same protection pattern. The difference is where configuration and state live.
import CircuitBreaker from 'opossum';
// Config defined in code
const breaker = new CircuitBreaker(callStripe, {
timeout: 3000,
errorThresholdPercentage: 50,
resetTimeout: 30000
});
const result = await breaker.fire();
// State is local to this instanceimport { OpenfuseCloud } from '@openfuseio/sdk';
// Config lives in the dashboard
const openfuse = new OpenfuseCloud({ ... });
const result = await openfuse
.breaker('stripe')
.protect(() => callStripe());
// See it break. Act before it spreads.When Opossum makes sense
If you're running a single Node.js service on a single instance, want zero external dependencies, and are comfortable managing breaker config in code, Opossum is a solid choice. It's battle-tested and does the job without adding infrastructure.
The tradeoffs appear when you scale past that: no way to see what your breakers are doing across instances, no way to act on them without deploying, and no unified view across services. If that sounds familiar, that's exactly the problem Openfuse was built to solve. And if zero external dependencies is non-negotiable, you can self-host the entire platform on your own infrastructure.
Frequently asked questions
Common questions about switching from Opossum to Openfuse.
Can I migrate from Opossum to Openfuse?
Yes. Openfuse's SDK has a similar protect() API, so the migration is straightforward. You replace the Opossum circuit breaker instantiation with Openfuse's breaker() call, and move your threshold configuration to the dashboard. Most teams migrate a single service in under an hour.
Do I need to change my application code significantly?
Minimal changes. The core pattern is the same: wrap your call in a protect function. The main difference is that configuration moves out of your code and into the Openfuse dashboard. Your business logic stays the same.
What happens if Openfuse goes down?
The SDK is fail-open by design. If our service is unreachable, it falls back to the last known breaker state. If no state has ever been cached (e.g., a cold start with no connectivity), it defaults to closed. Your protected calls keep executing normally, your app is never blocked by Openfuse unavailability. If you need full control over availability, you can self-host the entire platform on your own infrastructure. Same dashboard, same SDK, no external dependency.
Is Opossum still maintained?
Opossum is an open-source project with community maintenance. It's a solid library for what it does. The question isn't whether Opossum works, it's whether a local, per-instance circuit breaker gives you the visibility and control you need. If you're running multiple services or instances and want to see and act on failures across your fleet, that's where Openfuse comes in.
Can I use Openfuse alongside Opossum during migration?
Absolutely. You can migrate service by service at your own pace. Services using Openfuse will benefit from centralized state immediately, while services still on Opossum continue working as before.
Ready to build more resilient systems?
Start protecting your critical infrastructure in minutes. Free for up to 10 breakers on our cloud, or self-host from day one.